Indexing to the same base is a good way of normalising data to a common starting point.
This can be used to align economic data of different countries, e.g. jobs created or GDP (Gross Domestic Product), for easier comparison
In this way, it becomes easier to compare the data on a chart and thus to more intuitively see the changes over time
The formula for an index is to take the current value, divide it by the initial value and multiply by 100
X ̂_𝑡=(X_𝑡/X_0 )×100
In a similar fashion, you can make the index 1000 or 10000 by replacing the above 100
In the below example, a Quarterly GDP comparison of the USA vs Australia (in billions of Australian Dollars)
Due to the large difference between the GDPs, it is difficult to compare the changes.
See Example 1
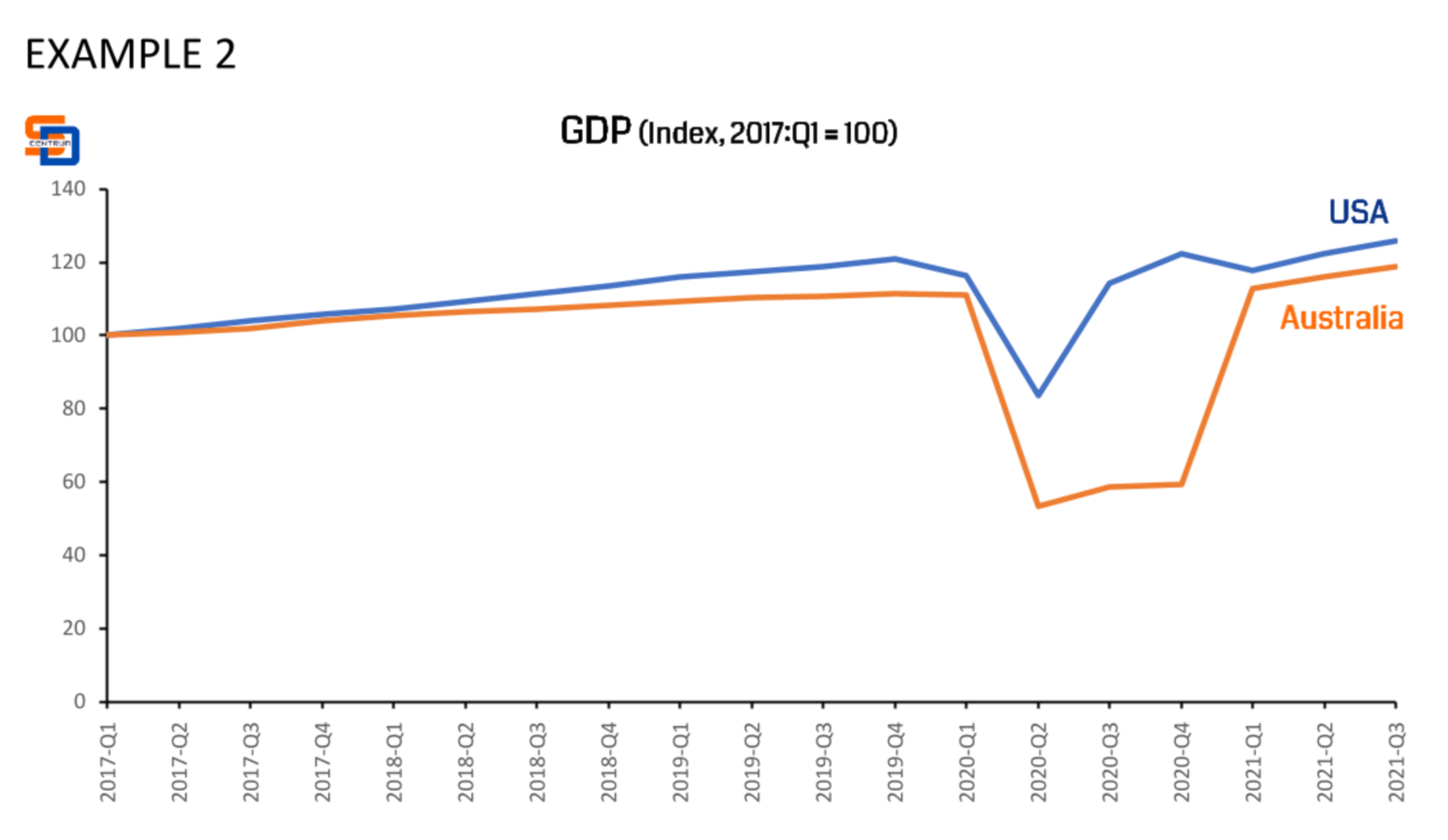
After re-indexing the numbers in Example 2 it becomes easier to see the changes in GDP between USA and Australia.
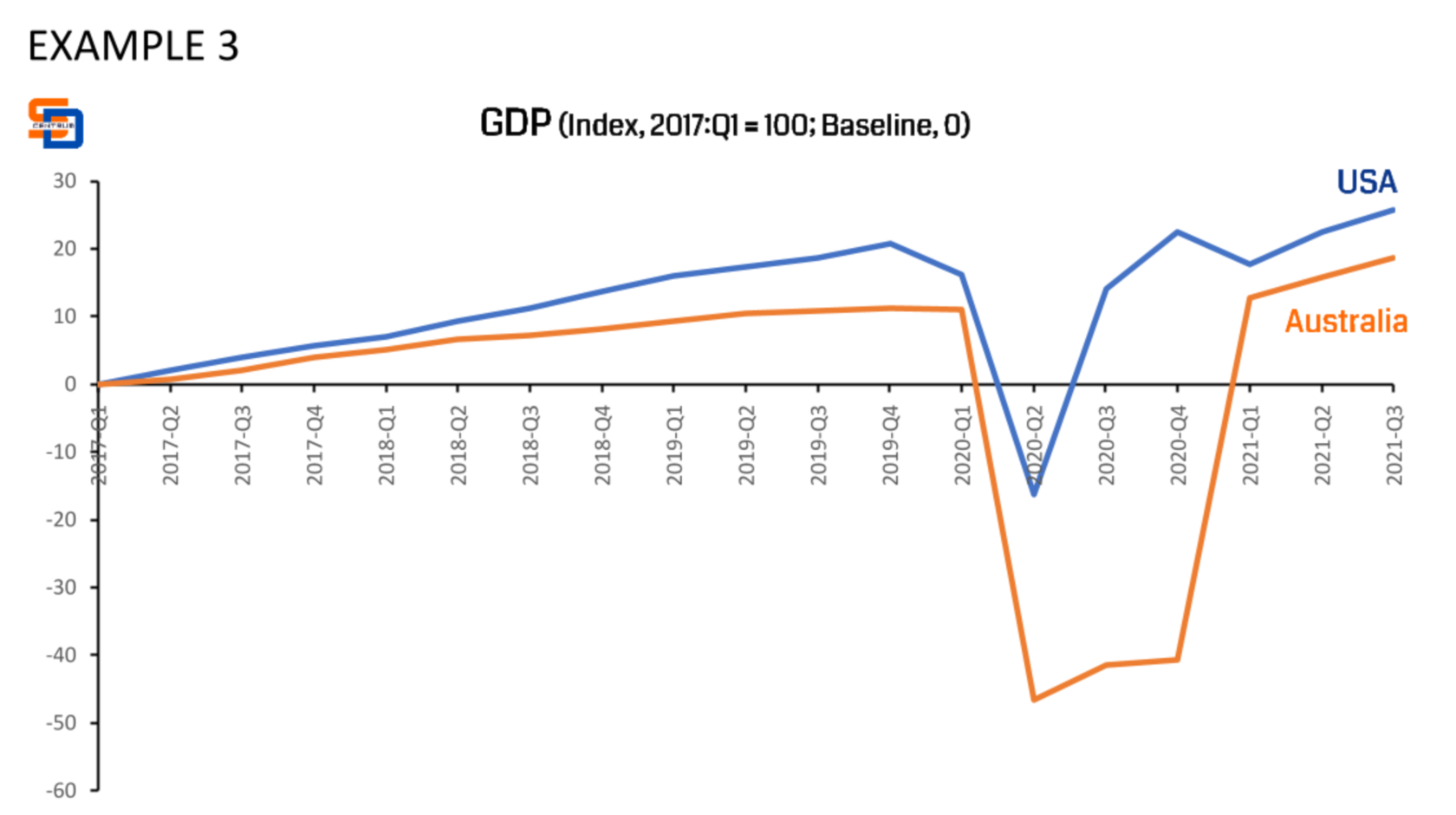
Now, if you set the baseline of the dataset to 0, like in Example 3, then you can see the differences in GDP change over time.
This can be used to align economic data of different countries, e.g. jobs created or GDP (Gross Domestic Product), for easier comparison
In this way, it becomes easier to compare the data on a chart and thus to more intuitively see the changes over time
The formula for an index is to take the current value, divide it by the initial value and multiply by 100
X ̂_𝑡=(X_𝑡/X_0 )×100
In a similar fashion, you can make the index 1000 or 10000 by replacing the above 100
In the below example, a Quarterly GDP comparison of the USA vs Australia (in billions of Australian Dollars)
Due to the large difference between the GDPs, it is difficult to compare the changes.
See Example 1
After re-indexing the numbers in Example 2 it becomes easier to see the changes in GDP between USA and Australia.
Now, if you set the baseline of the dataset to 0, like in Example 3, then you can see the differences in GDP change over time.