I found an interesting behaviour when inserting/updating Dataverse's lookup fields in DataFlows with ADF. The only instruction for the lookup fields you can find on the internet is about the "Copy" activity in the "Pipelines", which doesn't work for DataFlows. Exceptions you receive don't show any meaningful info, just generic errors. There is no simple solution on the internet. The only one I found was to use DataFlow to prepare and transfer the data to a blob file and then copy this data to Dataverse (by using the "Copy" activity in a Pipeline). But this is overcomplicated and costs extra $.
So, after several hours of intensive debugging and researching, an easier and a way cost cost-efficient solution was found. Here it is:
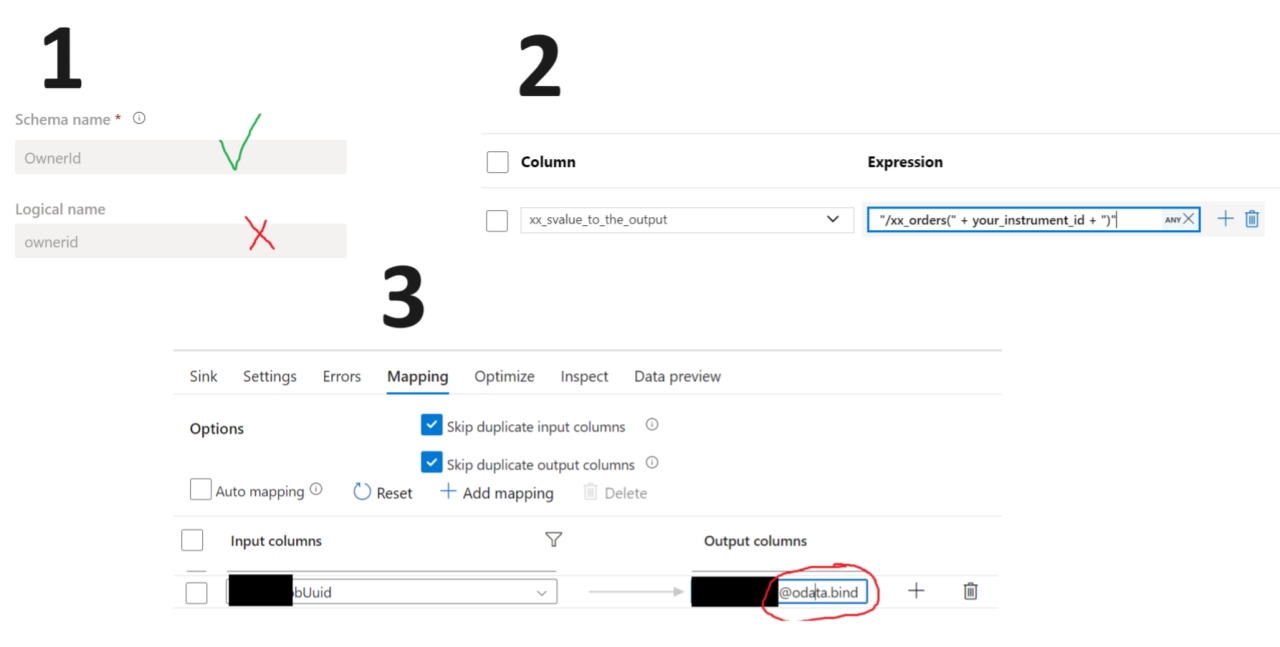
1) in the sink mapping, you set the lookup's destination column with schema name (which is usually PascalCased), and append @odata.bind so that the column name would look like xx_YourEntityId@odata.bind . Please note that for all other fields, you have to use LOGICAL NAME! I know...
2) the value you're passing to the column is "/xx_orders(xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx)" - ensure the entity name is PLURAL and lowercase!
3) to generate this value, you can use the "Derived Column" block, putting "/xx_orders(" + your_entirty_id + ")" into the expression field.
I hope this will save you many hours and nerves 🙂
Dear ADF team, you're building an awesome product, but could you please
1) standardize the names we use for data mapping. It's very confusing where to use logical and schema names working with Dataverse. Plus, the exceptions we got are not clear.
2) Simplify the mapping method for Lookup fields in Dataverse.
3) Add to your instructions Lookups mapping for Data Flows, because current instructions are about the pipelines only, which surprisingly has a different logic.
So, after several hours of intensive debugging and researching, an easier and a way cost cost-efficient solution was found. Here it is:
1) in the sink mapping, you set the lookup's destination column with schema name (which is usually PascalCased), and append @odata.bind so that the column name would look like xx_YourEntityId@odata.bind . Please note that for all other fields, you have to use LOGICAL NAME! I know...
2) the value you're passing to the column is "/xx_orders(xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx)" - ensure the entity name is PLURAL and lowercase!
3) to generate this value, you can use the "Derived Column" block, putting "/xx_orders(" + your_entirty_id + ")" into the expression field.
I hope this will save you many hours and nerves 🙂
Dear ADF team, you're building an awesome product, but could you please
1) standardize the names we use for data mapping. It's very confusing where to use logical and schema names working with Dataverse. Plus, the exceptions we got are not clear.
2) Simplify the mapping method for Lookup fields in Dataverse.
3) Add to your instructions Lookups mapping for Data Flows, because current instructions are about the pipelines only, which surprisingly has a different logic.
